第5回:データの整理(2)
クイズ
おさらい
- 前回は以下のデータ処理に必要な関数を学びました:
rename()で列の名前を変更するmutate()で列の中身を変えるarrange()で行を並び替えるfilter()で行を絞り込む
準備
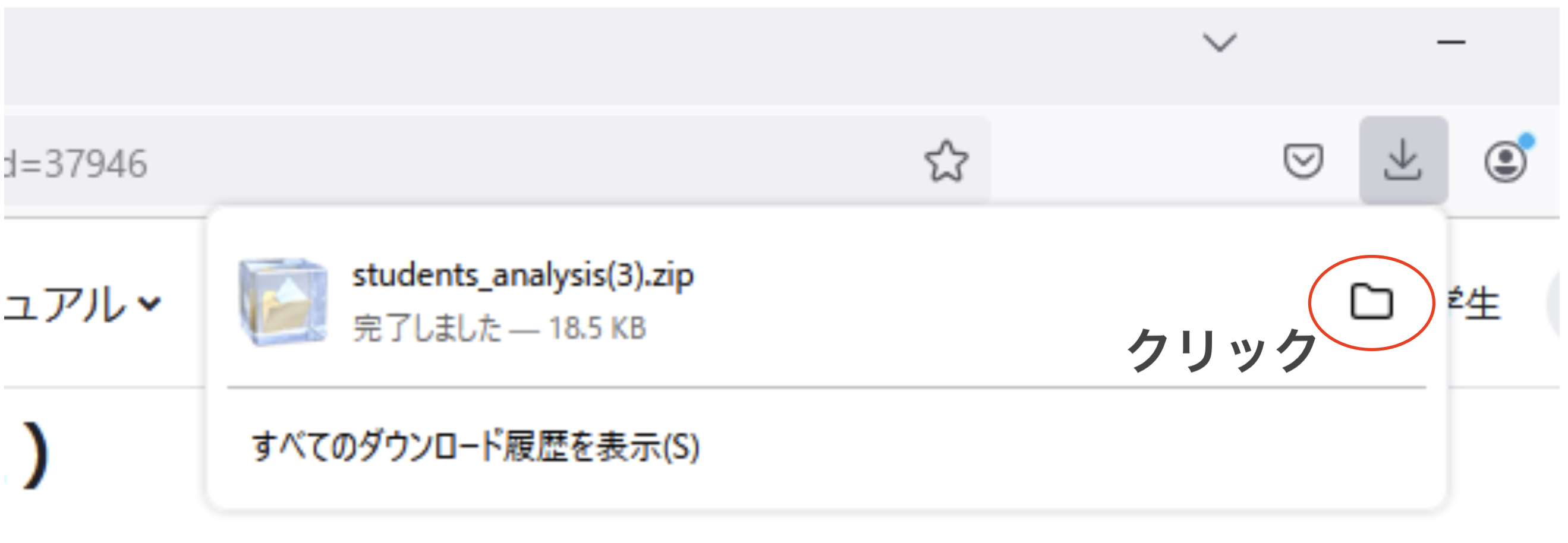
全員が同じ状態になるために、まずMoodleから第5回の
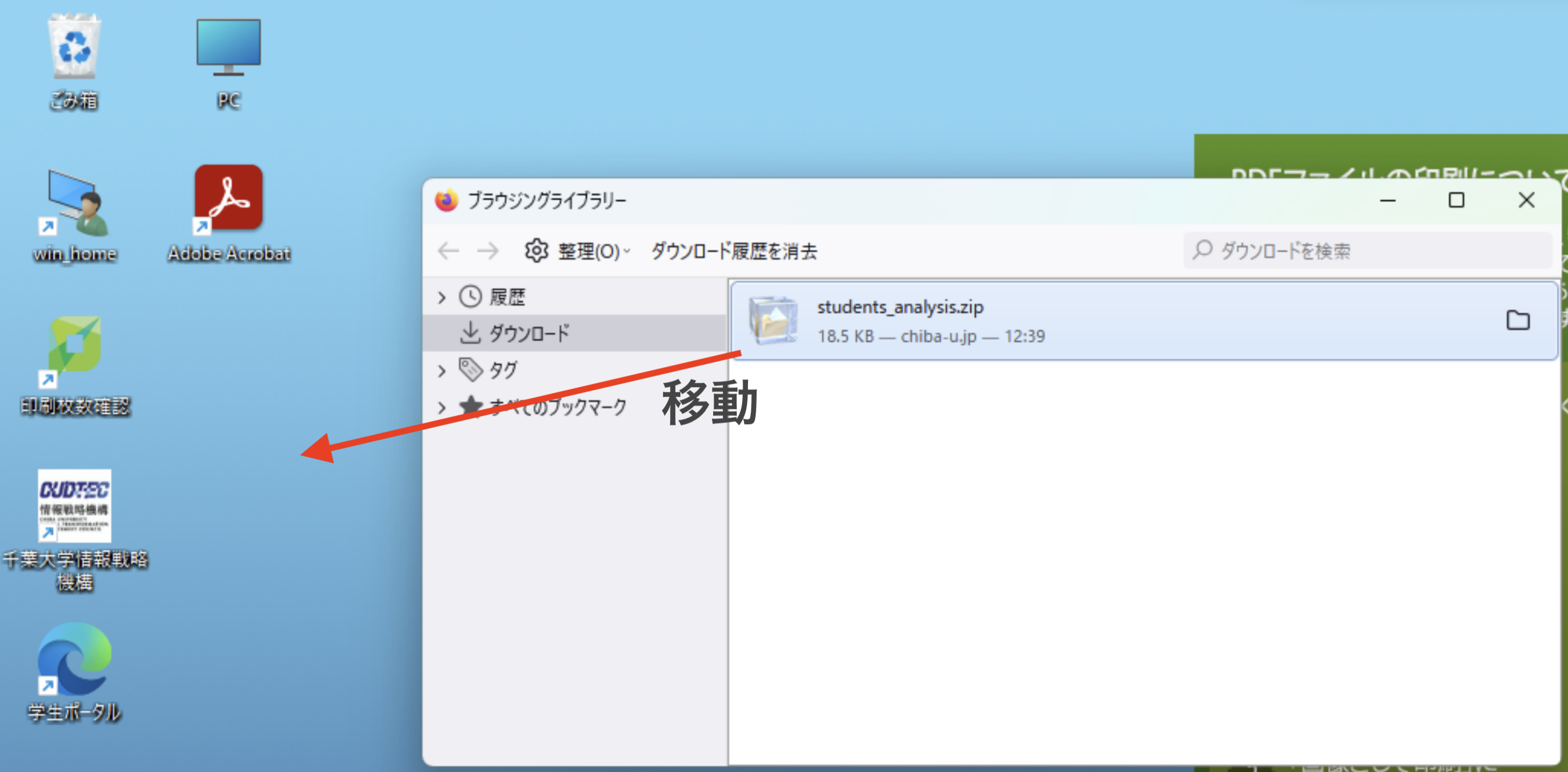
students_analysis_day5.zipをダウンロードして、デスクトップで解凍してください。デスクトップにある
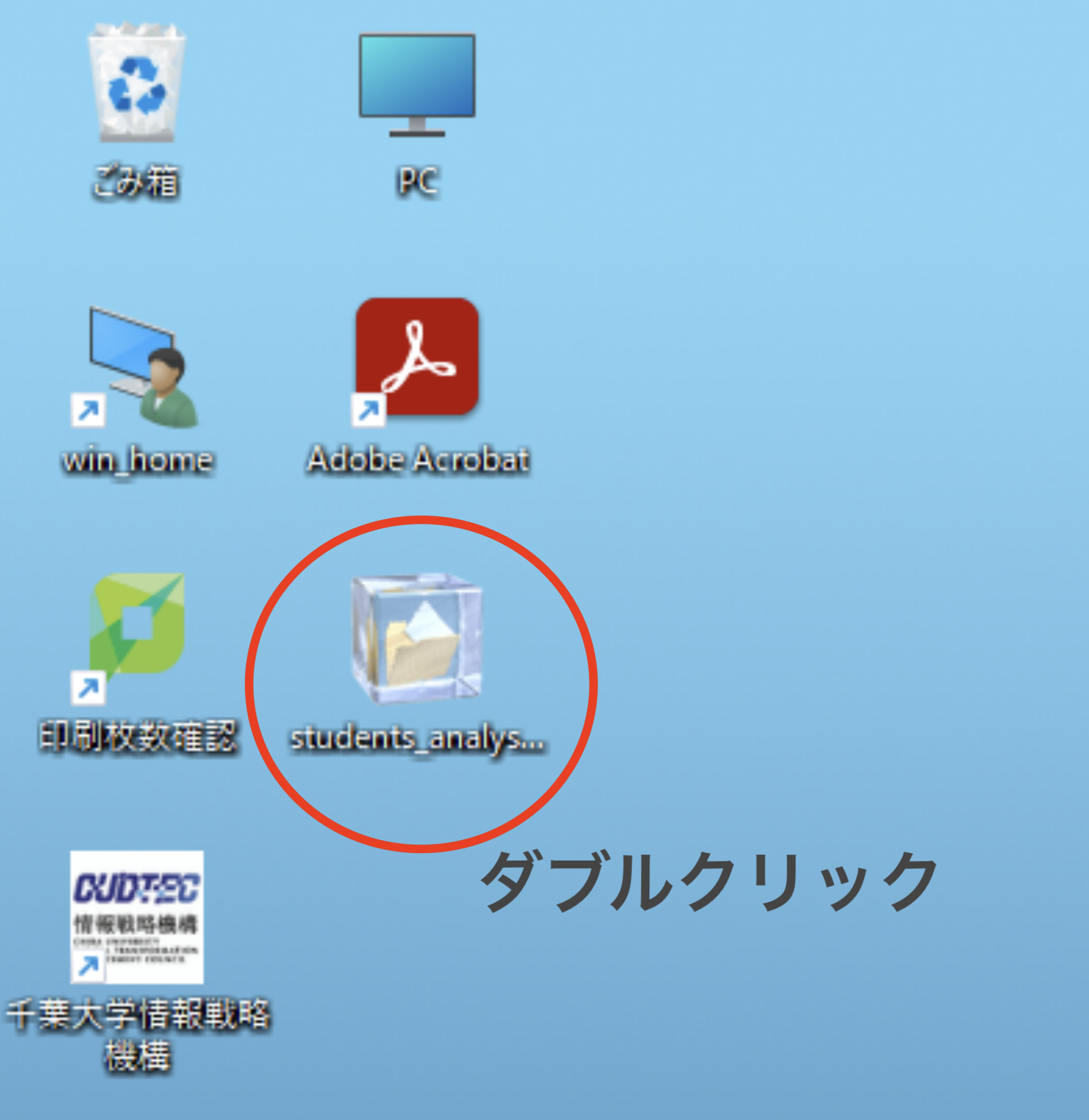
students_analysis_day5フォルダー内のstudents_analysis.Rprojをダブルクリックして、プロジェクトを開いてください。- FireFoxを使ってください。
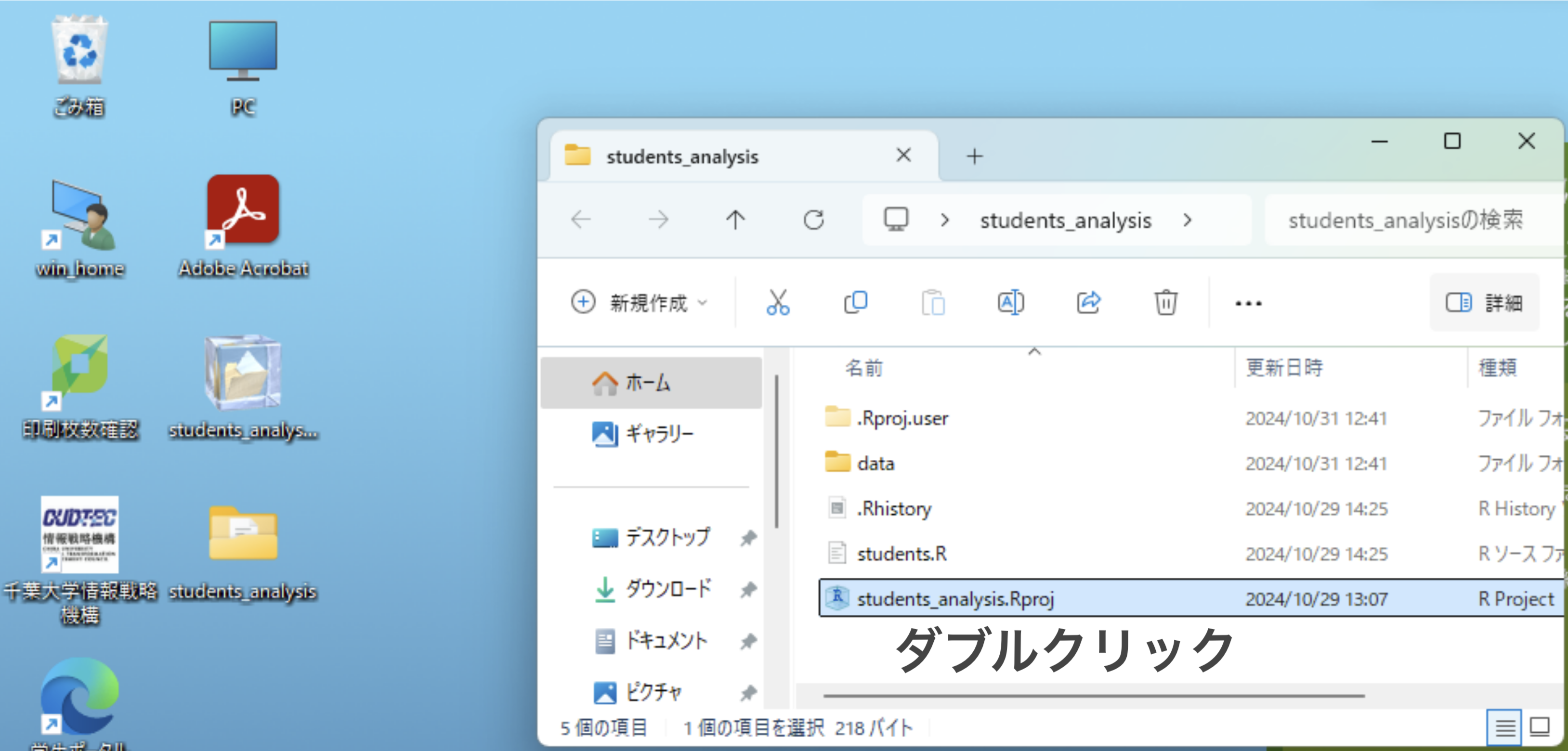
students.Rのコードを実行してデータを読み込み、整理してください。
チャレンジ ①
早速チャレンジに取り組みましょう。
studentsから食事プランが"Lunch only"の学生を抽出し、名前をZからAの順に並べ替えてください。
パイプについて
- チャレンジ①では、まず条件で絞り込んだデータを一時保存してから、次のステップ(列の並び替え)を行いました。
パイプについて
この方法でも解析が短い場合は問題ありませんが、長くなると大変です。
パイプを使うとこの問題を解決できます。
パイプの使い方
- まず、パイプ(
|>)の基本的な使い方を覚えましょう。- 以前は
%>%と書いていましたが、最近のRでは|>が使われます。
- 以前は
- 例えば、
arrange(データ, 列名)のように書いてきましたが、パイプを使うと次のように書けます:
データ |> arrange(列名)
- つまり、
|>は左側のものを右側へ渡す機能があります。
試してみましょう。
# A tibble: 6 × 5
student_id full_name favourite_food meal_plan age
<dbl> <chr> <chr> <chr> <dbl>
1 3 Jayendra Lyne N/A Breakfast and lunch 7
2 5 Chidiegwu Dunkel Pizza Breakfast and lunch NA
3 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
4 2 Barclay Lynn French fries Lunch only 5
5 4 Leon Rossini Anchovies Lunch only NA
6 6 Güvenç Attila Ice cream Lunch only 6- 繰り返しになりますが、
students |> arrange(meal_plan)
と
arrange(students, meal_plan)
は同じ意味です。
- パイプの便利な点は、途中結果を保存せずに解析のステップを次々と進められるところです。
# A tibble: 4 × 5
student_id full_name favourite_food meal_plan age
<dbl> <chr> <chr> <chr> <dbl>
1 2 Barclay Lynn French fries Lunch only 5
2 6 Güvenç Attila Ice cream Lunch only 6
3 4 Leon Rossini Anchovies Lunch only NA
4 1 Sunil Huffmann Strawberry yoghurt Lunch only 4- Rは改行があっても構いませんので、改行を入れるとさらに読みやすくなります。
# A tibble: 4 × 5
student_id full_name favourite_food meal_plan age
<dbl> <chr> <chr> <chr> <dbl>
1 2 Barclay Lynn French fries Lunch only 5
2 6 Güvenç Attila Ice cream Lunch only 6
3 4 Leon Rossini Anchovies Lunch only NA
4 1 Sunil Huffmann Strawberry yoghurt Lunch only 4|>を見たら、「それから」と読むと理解しやすいです:
studentsから始めて、それから食事プランが”Lunch only”の学生に絞り込んで、それから学生の名前順に並び替える
- 今後は基本的にパイプを使ってコードを書きます。
- 最初は慣れないかもしれませんが、すぐに馴染むでしょう。
チャレンジ ②
パイプを使ってstudentsからstudent_idが2より大きい行だけに絞り、favourite_foodの順で並び替えてください。
欠測データについて
ageにはNAという値が含まれています。NAは「Not Applicable」(「該当しない」)を意味します。- この値は、データが該当しないか、または欠損していることを示します。
ageの場合、何らかの理由でその人の年齢がわからないことを意味します。- (一部はうまく数字に変換できなかったためですが、もう一つは元々そうなっていました)
欠測データを省く方法
- データフレームに欠測データが含まれていると、エラーの原因になることが多いです。
- 解析を行う前にそれらを除外する必要があります。
is.na()関数は、その値がNAであるかを確認してくれます。
- 例えば:
使ってみましょう。
# A tibble: 2 × 5
student_id full_name favourite_food meal_plan age
<dbl> <chr> <chr> <chr> <dbl>
1 4 Leon Rossini Anchovies Lunch only NA
2 5 Chidiegwu Dunkel Pizza Breakfast and lunch NAあら、これはまずいですね。欠測データだけが抽出されてしまいました。
私たちが欲しいのは、その逆です。
!は論理ベクトルを反転させます。- つまり、
TRUEをFALSEに、FALSEをTRUEにします。「否」と読むと理解しやすいです。
- つまり、
!を使って、NAではないデータだけに絞り込みましょう。
# A tibble: 4 × 5
student_id full_name favourite_food meal_plan age
<dbl> <chr> <chr> <chr> <dbl>
1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
2 2 Barclay Lynn French fries Lunch only 5
3 3 Jayendra Lyne N/A Breakfast and lunch 7
4 6 Güvenç Attila Ice cream Lunch only 6チャレンジ ③
studentsからageがNAになっている行を除外してから、favorite_foodの順で並び替えてください。(パイプを使ってください)
列を選ぶ
特にデータが大きい場合、解析に不要な列があることがあります。
必要な列だけに絞ることで、解析がやりやすくなります。
- 列を選ぶ関数は
select()です。例えば、student_id、full_name、meal_planを選択します:
# A tibble: 6 × 3
student_id full_name meal_plan
<dbl> <chr> <chr>
1 1 Sunil Huffmann Lunch only
2 2 Barclay Lynn Lunch only
3 3 Jayendra Lyne Breakfast and lunch
4 4 Leon Rossini Lunch only
5 5 Chidiegwu Dunkel Breakfast and lunch
6 6 Güvenç Attila Lunch only 列や行を扱う関数
- 前回は以下のデータ処理に使用する関数を学びました:
rename()で列の名前を変更するmutate()で列の内容を変更するselect()で列を選択するarrange()で行を並び替えるfilter()で行を絞り込む
新しいプロジェクト:gapminder
これから学ぶ関数はもっと大きなデータで使用するため、新しいプロジェクトを作成します。
このプロジェクトでは
gapminderというデータセットを使用します。1952年から2007年までの各国の経済データが含まれています(第4回の課題でも使用しました)。
gapminderプロジェクトの作成
- デスクトップに
gapminder_analysisというプロジェクトを作成し、そのプロジェクトを開いてください。
- プロジェクトの作成方法については、第3回のスライドを参照してください。
gapminderプロジェクトの作成
- データをMoodleからダウンロードし、
gapminder_analysisの中に保存してください:
https://moodle.gs.chiba-u.jp/moodle/mod/resource/view.php?id=1444823
gapminderプロジェクトの作成
- 新しいプロジェクト内に
gapminder.RというRファイルを作成し、gapminderというデータセットを読み込むコードを書きます:
データの集計
今まで学んだ関数はデータフレームの値を個別に扱いました(主に列か行に対する処理を行ってきました)。
しかし、データフレームに含まれる値の平均や合計を計算したい場合には、さらに操作が必要です。
データの合計をcount()で数える
データの全体像を掴むために、まず数を数えることは有効です。
例えば、
gapminderにいくつの国が含まれているかを数えます。- 注意:
count()のような集計関数の結果は、入力のデータと大きく異なります!
- 注意:
データの平均などを計算するためにsummarize()を使う
summarize()(「集計する」)の使い方はmutate()と似ています。summarize(データ, 新しい列名 = コマンド)- コマンドには、新しい列の生成方法を指定します
- 新しい列名の設定は任意であり、わかりやすい名前を指定します。
- 例えば、全体の寿命の平均を計算しましょう:
mean()は平均を計算する関数です。
- また、最も短い寿命を求めます:
min()は最小値を返す関数です。
summarize()によく使う計算のコマンド
集計をする際、以下の関数を覚えておくと便利です:
max():最大値を計算するmin():最小値を計算するmean():平均値を計算するsd():標準偏差を計算するn():それぞれのグループごとのデータの数(行数)を数える
グループ化
しかし、全体の平均や最小値だけでは役立ちません。
代わりに、国ごとの値が知りたい場合があります。
そのように「何かごと」に計算するには、グループ化を使用します。
- グループを指定する関数は
group_by()です:
# A tibble: 1,704 × 6
# Groups: country [142]
country year pop continent life_exp gdp_percap
<chr> <dbl> <dbl> <chr> <dbl> <dbl>
1 Afghanistan 1952 8425333 Asia 28.8 779.
2 Afghanistan 1957 9240934 Asia 30.3 821.
3 Afghanistan 1962 10267083 Asia 32.0 853.
4 Afghanistan 1967 11537966 Asia 34.0 836.
5 Afghanistan 1972 13079460 Asia 36.1 740.
6 Afghanistan 1977 14880372 Asia 38.4 786.
7 Afghanistan 1982 12881816 Asia 39.9 978.
8 Afghanistan 1987 13867957 Asia 40.8 852.
9 Afghanistan 1992 16317921 Asia 41.7 649.
10 Afghanistan 1997 22227415 Asia 41.8 635.
# ℹ 1,694 more rowsこれで国ごとのグループが作成されました
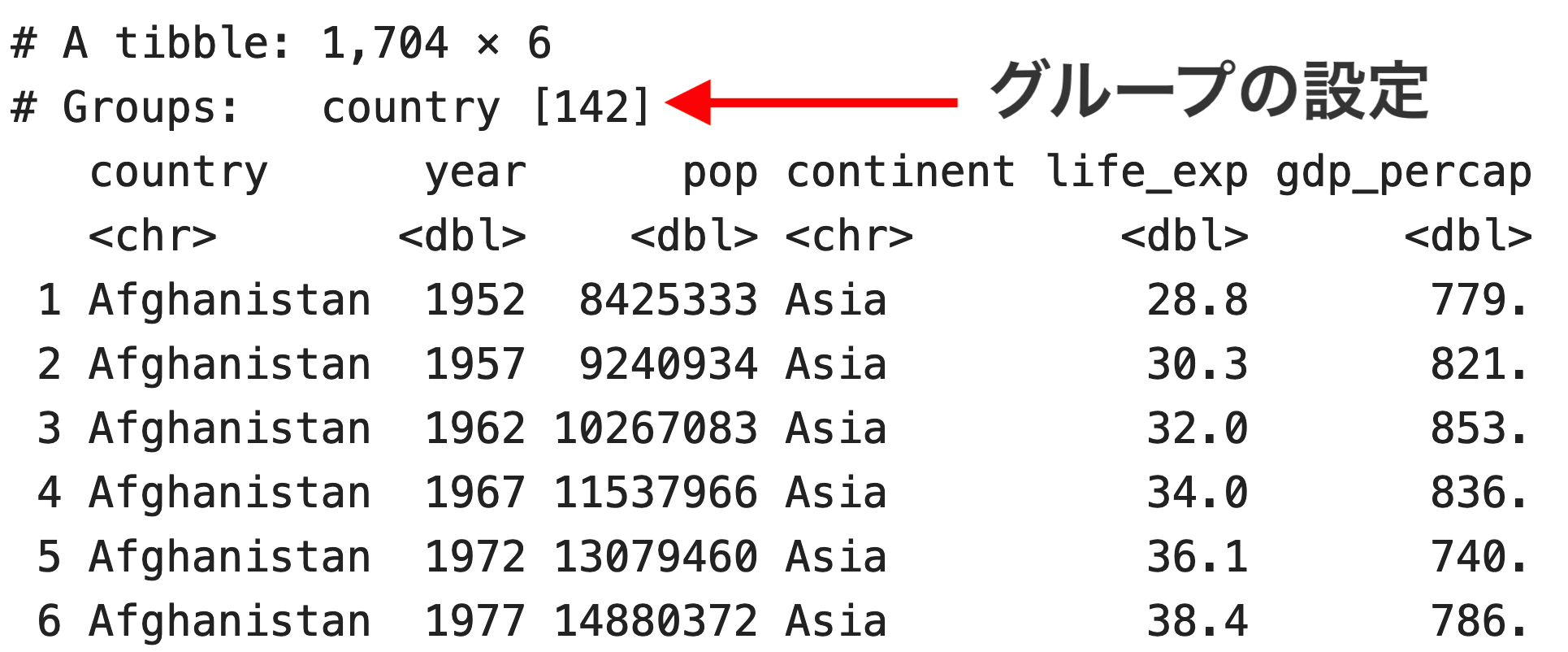
ただし、グループ化だけではまだ計算が行われていません。
グループ化の次に
summarize()を用いて計算します:
# A tibble: 142 × 2
country mean_life_exp
<chr> <dbl>
1 Afghanistan 37.5
2 Albania 68.4
3 Algeria 59.0
4 Angola 37.9
5 Argentina 69.1
6 Australia 74.7
7 Austria 73.1
8 Bahrain 65.6
9 Bangladesh 49.8
10 Belgium 73.6
# ℹ 132 more rowsチャレンジ ④
- 国ごとに寿命の最小値を求めてください。
グループ化
- 同時に複数の計算も可能です。
- 各新しい列をカンマで区切ります
- 例えば、平均と標準偏差:
# A tibble: 142 × 3
country mean_life_exp sd_life_exp
<chr> <dbl> <dbl>
1 Afghanistan 37.5 5.10
2 Albania 68.4 6.32
3 Algeria 59.0 10.3
4 Angola 37.9 4.01
5 Argentina 69.1 4.19
6 Australia 74.7 4.15
# ℹ 136 more rowssd()(「standard deviation」)は標準偏差を計算する関数です。
チャレンジ ⑤
- 国ごとの一人当たり総生産の平均と標準偏差を計算してください。
パイプライン
パイプとコマンドを組み合わせることで、複雑なデータ処理を簡単に行うことができます。
例えば、アジアの国だけに絞ってから、国ごとの計算も可能です:
gapminder |>
filter(continent == "Asia") |>
group_by(country) |>
summarize(
mean_life_exp = mean(life_exp),
sd_life_exp = sd(life_exp)
)# A tibble: 33 × 3
country mean_life_exp sd_life_exp
<chr> <dbl> <dbl>
1 Afghanistan 37.5 5.10
2 Bahrain 65.6 8.57
3 Bangladesh 49.8 9.03
4 Cambodia 47.9 8.93
5 China 61.8 10.3
6 Hong Kong China 73.5 6.69
7 India 53.2 9.26
8 Indonesia 54.3 11.5
9 Iran 58.6 8.98
10 Iraq 56.6 5.74
# ℹ 23 more rowsまとめ
- グループ化により、グループごとの集計が可能です。
group_byでグループを定義summarize()でグループごとの計算を実行
- パイプ(
|>)で複数のデータ処理操作をつなぐことで、複雑なデータ処理パイプラインが構築できます。