第6回:データの結合、可視化(1)
連絡事項
- 締め切りが迫っています
- オンデマンド回の課題:2025年11月17日(月) 23:59
- 倫理教育e-learning:2025年11月20日(木) 23:59
早めの提出を心がけてください。
クイズ
データの結合
データの結合
多くの場合、使用したいデータが複数のデータセット(データフレーム、あるいはファイル)にまたがっている。
そのため、データの結合(join)を行う必要がある。
今回は飛行データを使用してデータの結合方法を学びます。
プロジェクトの準備
新しいデータセットを解析するため、新しいプロジェクトを作りましょう。
flights_analysisというプロジェクトを作成し、デスクトップに保存してください。
パッケージの準備
- プロジェクト内に
flights.Rという新しいスクリプトを作成し、以下のコードを書きます:
nycflights13パッケージについて
このパッケージには複数の練習用データセットが含まれています。
flightsというデータフレームは2013年のニューヨーク市発の飛行データです。

複数のデータセットの例:飛行データ
flightsと入力すると、飛行データが表示されます:
# A tibble: 336,776 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>- ただし、データが多いため、この授業で使用する列を選んで、
flights2として保存しましょう:
# A tibble: 336,776 × 6
year time_hour origin dest tailnum carrier
<int> <dttm> <chr> <chr> <chr> <chr>
1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA
2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA
3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA
4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6
5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL
6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA
7 2013 2013-01-01 06:00:00 EWR FLL N516JB B6
8 2013 2013-01-01 06:00:00 LGA IAD N829AS EV
9 2013 2013-01-01 06:00:00 JFK MCO N593JB B6
10 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA
# ℹ 336,766 more rows複数のデータセットの例:航空会社データ
airlinesには航空会社の名称が含まれています。carrierは航空会社コード(二文字)を表しています。例えば、全日空のコードはNHです。
# A tibble: 16 × 2
carrier name
<chr> <chr>
1 9E Endeavor Air Inc.
2 AA American Airlines Inc.
3 AS Alaska Airlines Inc.
4 B6 JetBlue Airways
5 DL Delta Air Lines Inc.
6 EV ExpressJet Airlines Inc.
7 F9 Frontier Airlines Inc.
8 FL AirTran Airways Corporation
9 HA Hawaiian Airlines Inc.
10 MQ Envoy Air
11 OO SkyWest Airlines Inc.
12 UA United Air Lines Inc.
13 US US Airways Inc.
14 VX Virgin America
15 WN Southwest Airlines Co.
16 YV Mesa Airlines Inc. 飛行データと航空データの結合
どのようにして飛行データに航空会社の名前を結合させることができるでしょうか?
チャレンジ ①
まずは、列を確認しましょう。
二つのデータフレーム間で共通している列名はどれでしょうか?
この列名を基にデータの結合を行います。
left_join()で他のデータフレームからデータを加える
- データの結合には
left_join()関数を使用します。- 左側のデータに新しいデータを結合するという意味です。
航空会社の名前を追加しましょう:
# A tibble: 336,776 × 7
year time_hour origin dest tailnum carrier name
<int> <dttm> <chr> <chr> <chr> <chr> <chr>
1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA United Air Lines Inc.
2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA United Air Lines Inc.
3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA American Airlines Inc.
4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 JetBlue Airways
5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL Delta Air Lines Inc.
6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA United Air Lines Inc.
7 2013 2013-01-01 06:00:00 EWR FLL N516JB B6 JetBlue Airways
8 2013 2013-01-01 06:00:00 LGA IAD N829AS EV ExpressJet Airlines I…
9 2013 2013-01-01 06:00:00 JFK MCO N593JB B6 JetBlue Airways
10 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA American Airlines Inc.
# ℹ 336,766 more rows結合する際の「鍵」の重要性
上のコードを実行すると、このメッセージが表示されました:
Joining with `by = join_by(carrier)`つまり、各データフレームが共通して持っている列を基に結合しました。この列を「鍵」(Key)と呼びます。
共通する列がないと、結合はできません。
結合する際の「鍵」の重要性
上記のコードは自動的に共通する列を鍵として使用しましたが、手動で指定することも可能です:
# A tibble: 336,776 × 7
year time_hour origin dest tailnum carrier name
<int> <dttm> <chr> <chr> <chr> <chr> <chr>
1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA United Air Lines Inc.
2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA United Air Lines Inc.
3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA American Airlines Inc.
4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 JetBlue Airways
5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL Delta Air Lines Inc.
6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA United Air Lines Inc.
7 2013 2013-01-01 06:00:00 EWR FLL N516JB B6 JetBlue Airways
8 2013 2013-01-01 06:00:00 LGA IAD N829AS EV ExpressJet Airlines I…
9 2013 2013-01-01 06:00:00 JFK MCO N593JB B6 JetBlue Airways
10 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA American Airlines Inc.
# ℹ 336,766 more rows鍵となる列の条件
右側のデータの鍵は行を一意に識別できる必要があります。つまり、それぞれの
carrierはデータ内に一度だけ出現することが必要です。count()を使用して確認できます。
nが全て1になっていることを確認します。
これはfilter()を使用して確認できます:
# A tibble: 0 × 2
# ℹ 2 variables: carrier <chr>, n <int>nが全て1なので、航空会社コードがすべて一度だけ出現していることが確認できました。
他のデータの結合
nycflights13パッケージには他にもいくつかのデータフレームがあります:
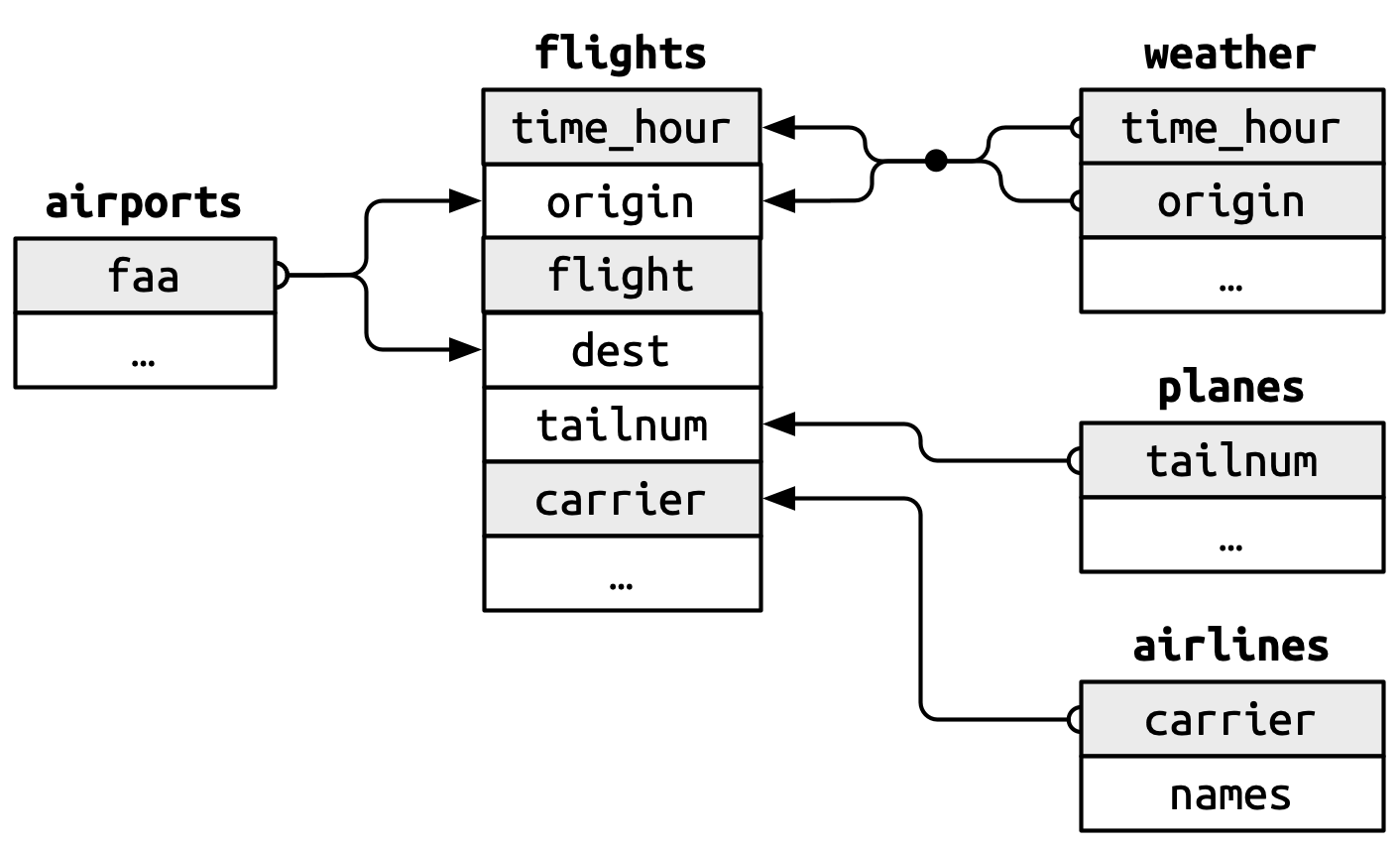
チャレンジ ②:他のデータの結合
飛行機データを含むplanesのデータフレームをflights2に結合できますか?
データの可視化
データの可視化について
EDA(Exploratory Data Analysis)において、データの可視化は重要なツールです。
本授業では
ggplot2パッケージを使用します。- Rの
plot()関数もありますが、統一性に欠け、使いにくいため、使用しません。
- Rの

Image by Allison Horst
ggplot2について
ggは”Grammar of Graphics”(図の文法)の略です。- 「文法」を理解すれば、(ほとんど)どんな図でも作成可能です。
(ggplotという旧バージョンのパッケージもありましたが、ggplot2はその新バージョンです)
ggplot2について
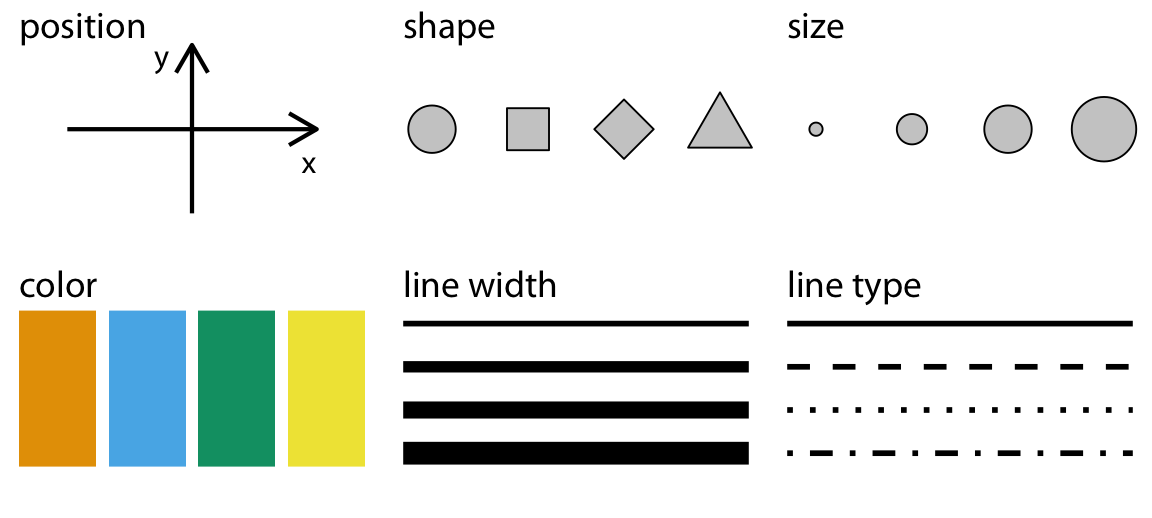
図の構造にはいくつかの決まった要素があります。
- geometry: 図の形
- aesthetics: データの図への表現
Geometry(形)
円グラフ
棒グラフ
Aesthetics(データの表現方法)
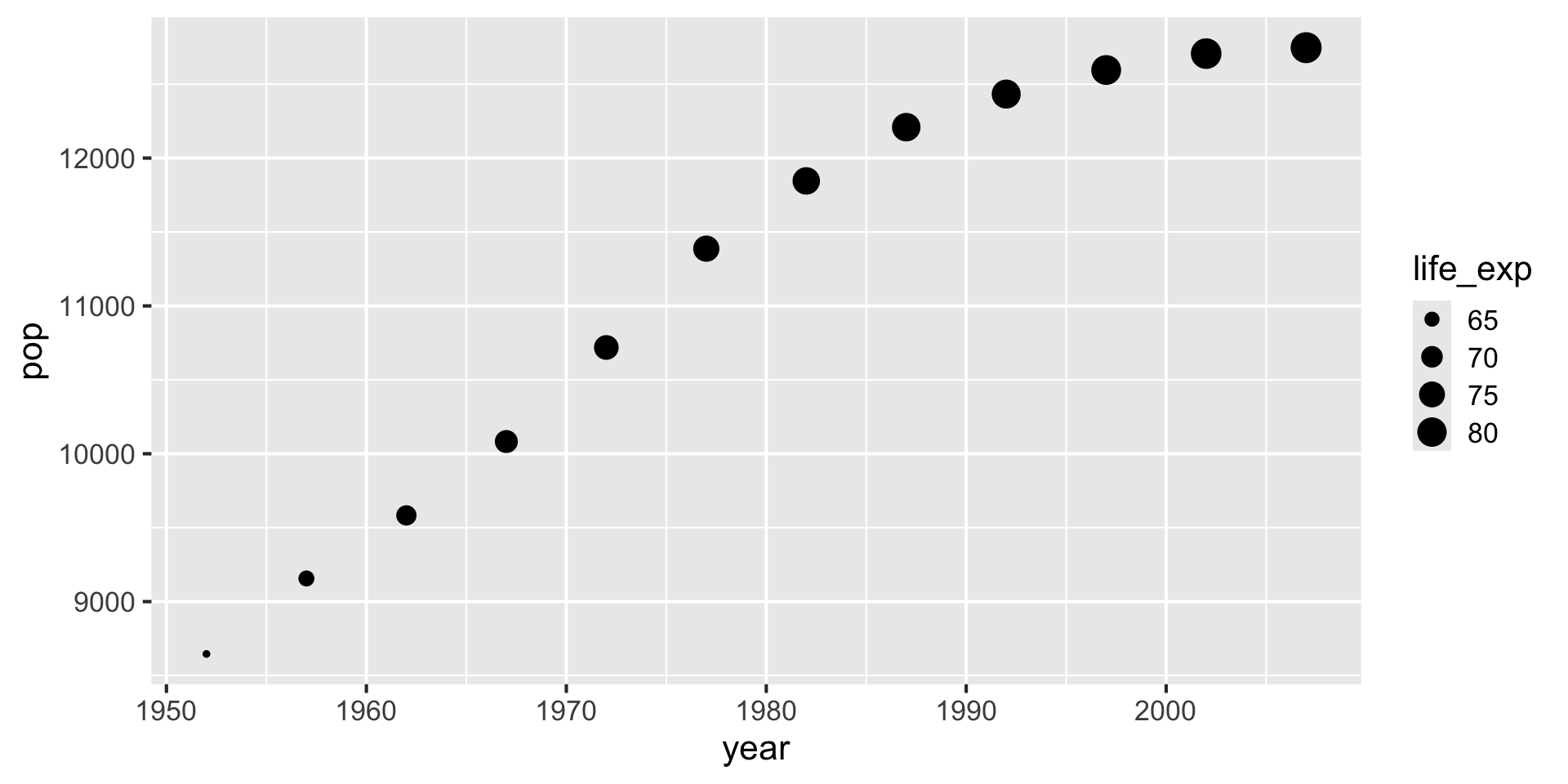
図の文法
- Geometry(形):点グラフ
- Aesthetics(データの表現方法)
year(年): 横軸(x)pop(人口、万人単位): 縦軸(y)life_exp(寿命):点のサイズ
プロジェクトの準備
新しいデータセットを解析するため、新しいプロジェクトを作成しましょう。
penguins_analysisというプロジェクトを作成し、デスクトップに保存してください。
パッケージの準備
- プロジェクト内に
penguins.Rという新しいスクリプトを作成し、以下のコードを書きます:
# A tibble: 344 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen NA NA NA NA
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
7 Adelie Torgersen 38.9 17.8 181 3625
8 Adelie Torgersen 39.2 19.6 195 4675
9 Adelie Torgersen 34.1 18.1 193 3475
10 Adelie Torgersen 42 20.2 190 4250
# ℹ 334 more rows
# ℹ 2 more variables: sex <fct>, year <int>
palmerpenguinsについて

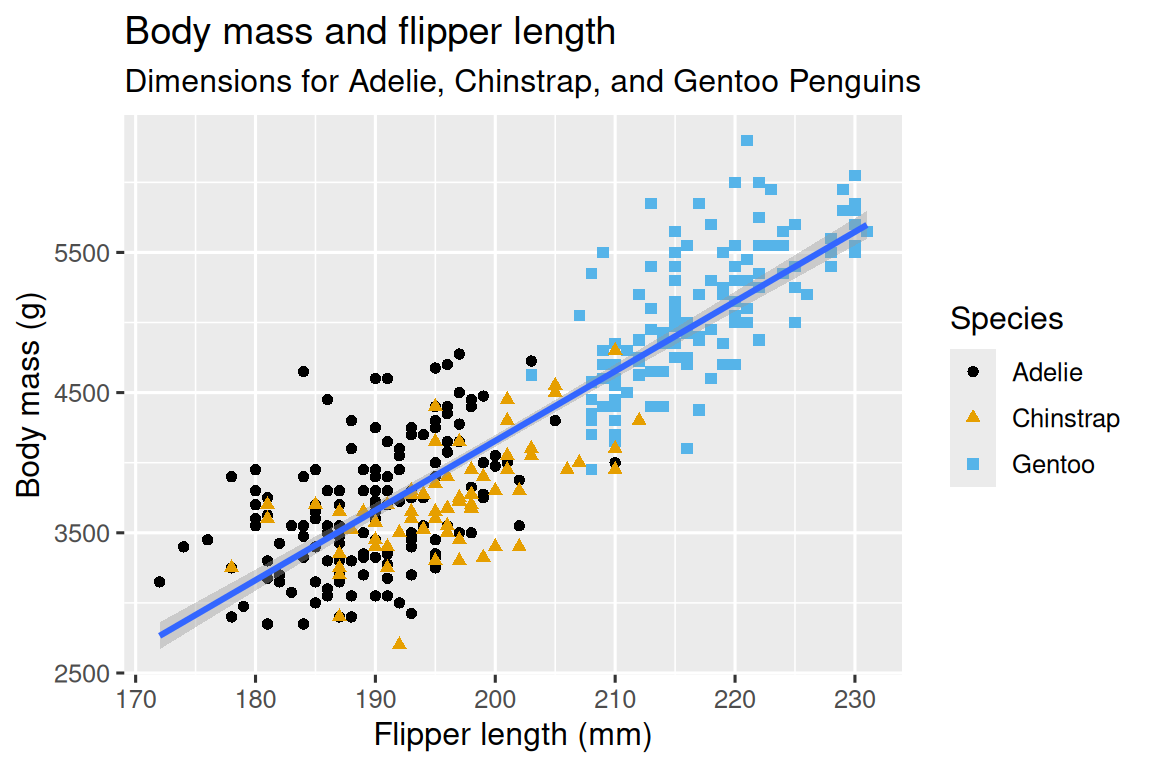
目的:このグラフを作成する
ggplot()でグラフの基盤を作成する

mapping()で座標を指定する
mapping()で座標を指定する
geom_()でデータの形を指定する
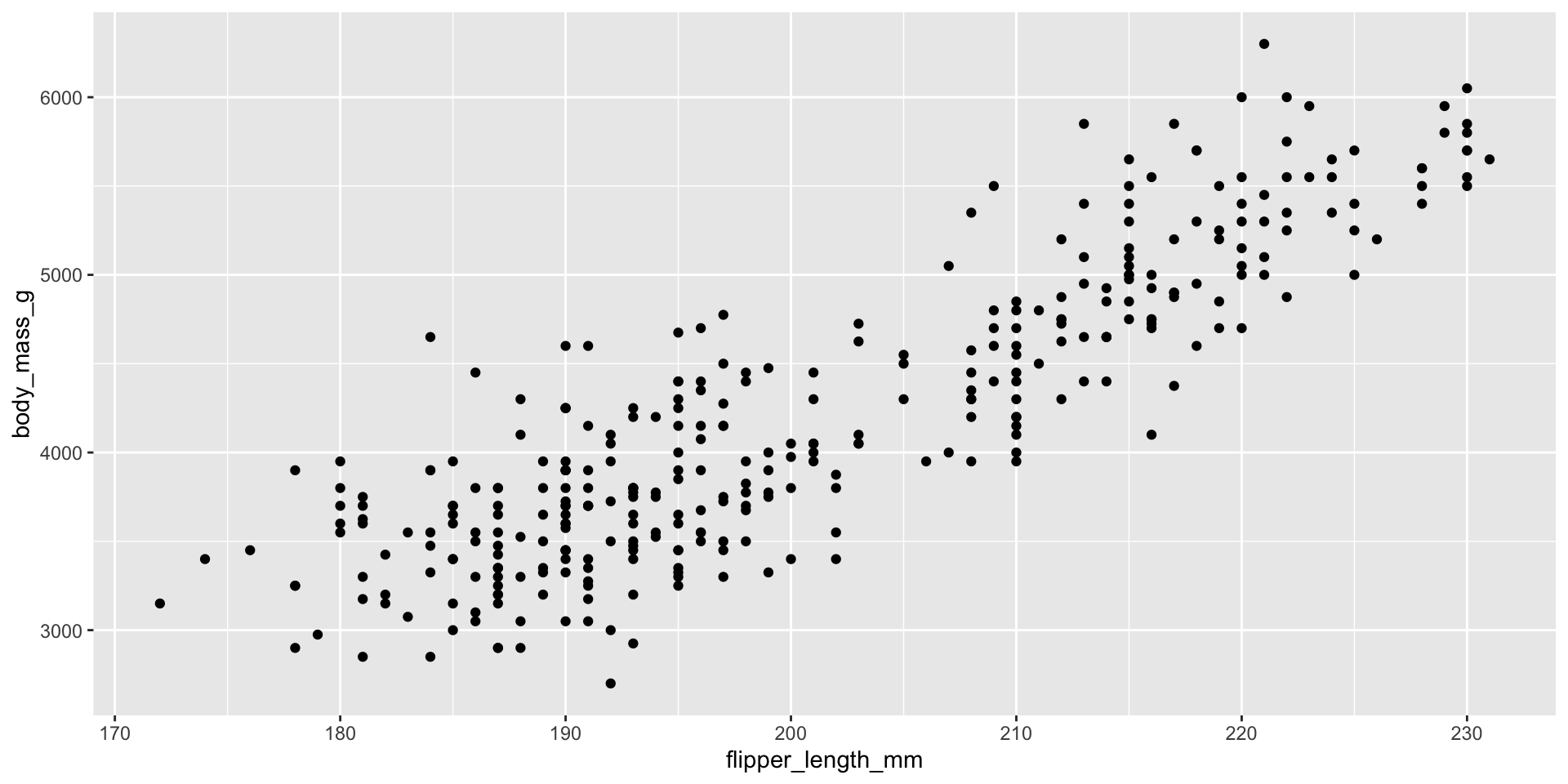
geom_()でデータの形を指定する
チャレンジ ③
bill_length_mmを横軸、bill_depth_mmを縦軸にして、点グラフを作成してください。
colorで色を付ける
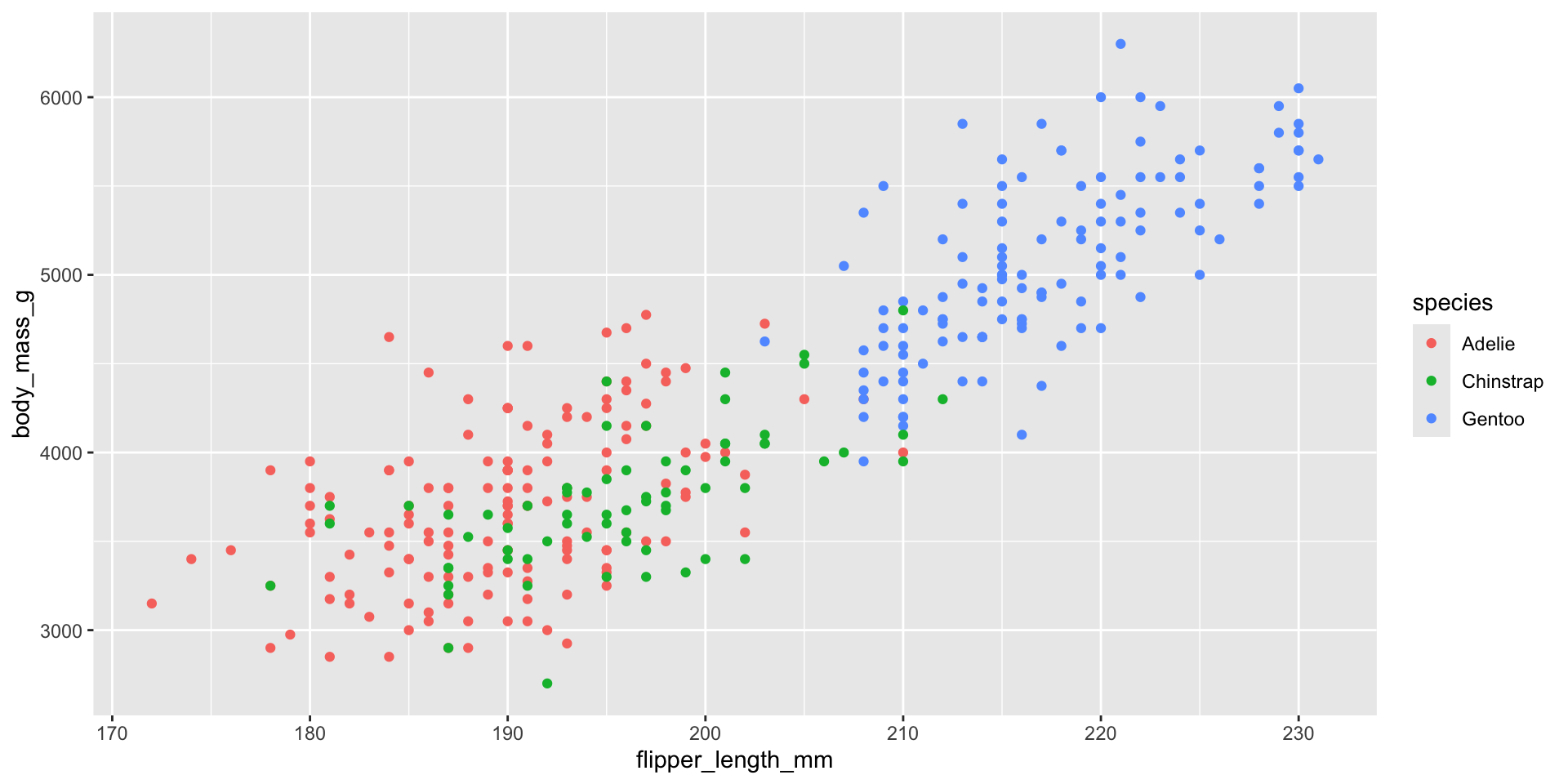
colorで色を付ける
チャレンジ ④
色で島(island)を表現してください。
チャレンジ ⑤
色で種(species)、形で島(island)を表現してください。